First a disclaimer: I am not an expert on artificial intelligence or its applications in product design. My thoughts below on where AI may have the biggest impact in PLM are based on research and theory, not hands-on experience developing or implementing these technologies. The potential of AI is vast and rapidly evolving, so predictions about its future are imperfect by nature. My goal is not to present definitive claims, but rather to provoke thoughtful consideration about how AI might transform design and PLM in the years ahead.
Like many, I was intrigued when ChatGPT made headlines and my initial impressions were dismissing it as merely a text generator – perhaps helpful for marketing content or student essays, but not groundbreaking. However, the next generation of AI tools like text-to-image, text-to-video, and text-to-audio revealed the immense possibilities of large language models (LLMs) like those that power ChatGPT. As the capabilities of language models continued to rapidly advance, I realized how badly I had underestimated the profound relationships between language, the human mind, and other modalities like images, video, and audio.
LLMs have shown astonishing abilities to generate realistic media from textual descriptions. This links back to the deep connections between language and human cognition – our minds conceptualize the world largely through language. I now see that these capabilities could massively transform many aspects of PLM. In the following article, I will share my perspective on where LLMs seem poised to have the biggest impact within PLM, particularly on reinventing and enhancing design processes.
How ChatGPT works
At a basic level, ChatGPT works by just predicting the next word to add to a sequence of text. This is done by looking at the probabilities of different words appearing after a given sequence of words. The probabilities are calculated based on the data that ChatGPT was trained on. To add some randomness to the text that it generates, it also introduce a small amount of noise into the prediction process. This helps to avoid repetitive text and the big surprise is that such a method can produce coherent, human-sounding text.
To generate text, ChatGPT uses a neural network with 175 billion weights, comparable to the number of words in its training data. This large number of weights allows it to learn the complex relationships between words and to generate text that is both informative and creative.
The surprising abilities and limits of LLM
Neural networks are a type of machine learning model that are inspired by the structure of the human brain. They are made up of interconnected nodes, called neurons, organized in layers, that transmit signals to each other. These networks are trained on data to learn complex patterns and relationships. Neural networks excel at solving problems where traditional algorithms may struggle, including classification, regression, and clustering.
A large language model (LLM) is a type of neural network that is trained on a massive dataset of text. This allows them to learn the statistical relationships between words and phrases, which can be used to generate text, translate languages, write different kinds of creative content, and answer questions in an informative way.
Training involved exposing the neural network to hundreds of billions of words from the web, books, articles, code, & other sources and then adjusting the weights of the network so that it could generate text that was similar to the text in the dataset. Additional feedback from humans then further tuned the network to generate more human-like text. It is able to use new information provided at prompt time because it is able to combine pre-existing knowledge in new ways. For example, if you ask ChatGPT to write a poem about a cat, it can use its knowledge of cats, poems, and language to generate a new poem.
There are limits to what neural networks like ChatGPT can learn. They cannot readily capture computationally irreducible processes, which are processes that cannot be broken down into smaller steps. For example, ChatGPT cannot learn how to play chess, because chess is a computationally irreducible process.
However, ChatGPT ‘s ability to learn from a massive dataset of text and code suggests that there are simpler “laws” behind human thinking than we realized. In language, these laws may include things like syntax, logic, and semantics. Its strengths and weaknesses provide clues to how language works in the human mind.
How image generation AIs like Midjourney work
Midjourney uses a type of AI known as a diffusion model for image generation.
A diffusion model is a type of generative model that works by starting with a random image and then gradually adding noise to it. The noise is then reversed to create a more realistic image. Diffusion models can be used to generate images, videos, and even 3D models.
These models are also trained on large datasets of images. Specifically, Midjourney is trained on hundreds of millions of images matched to text captions describing their content. This dataset helps the model learn the associations between textual descriptions and corresponding visual content.
After the training process, Midjourney can take a text prompt and generate images that correspond to the textual descriptions. It essentially leverages its learned knowledge of visual patterns to generate new images based on the given text.
Limitations include the AI having no true semantic understanding of the images or prompts. It cannot reason about the physical plausibility of generated scenes or objects. As a result, it may produce visually plausible but physically impossible scenes. For example, it can generate human-figures with extra limbs or images with unrealistic textures.
What Is a Model anyway?
Say you want to know how the cost of a product will vary depending on the number of units produced. Well, you could just measure it for different production volumes and make a table of the results. Or you could do what is the essence of data science: make a model that gives a procedure for estimating the cost rather than just measuring and remembering each case.
Let’s imagine we have (somewhat idealized) cost data for different production volumes:
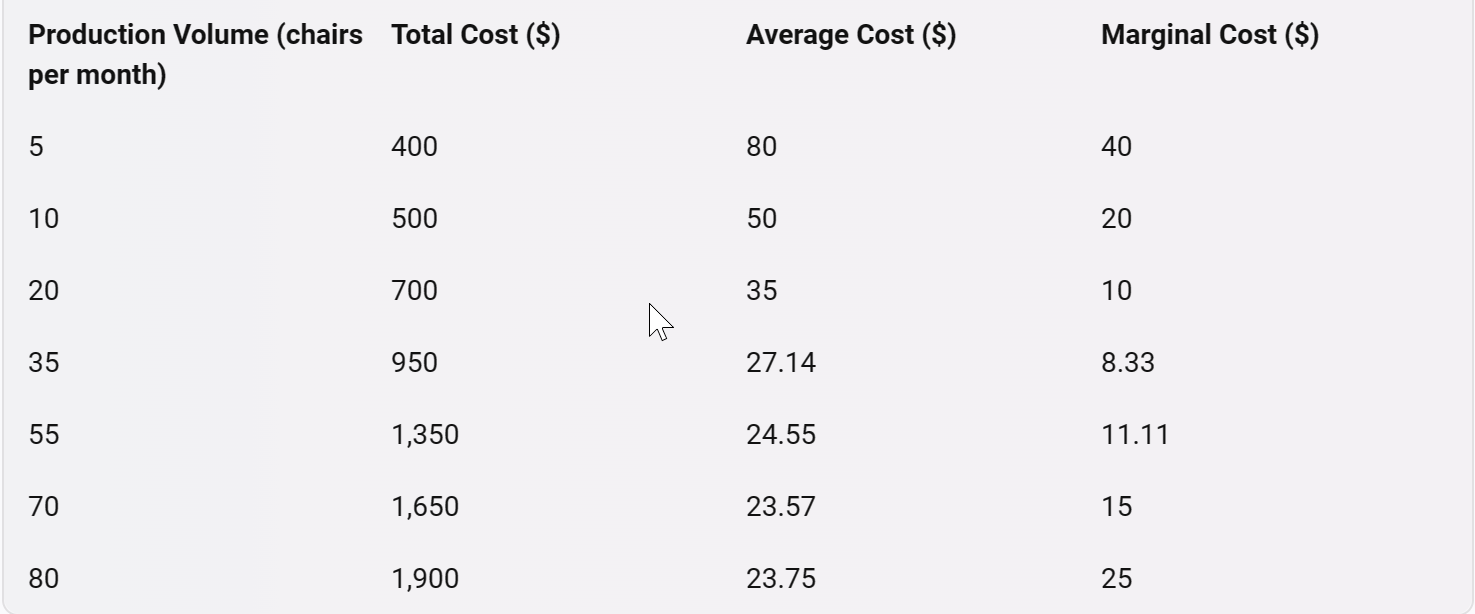
How do we figure out the cost for a volume we don’t have data for? In this particular case, we can derive a model from manufacturing principles and processes. But say all we’ve got is the data, and we don’t know the underlying drivers. Then we might make a mathematical guess, like using a straight line model:
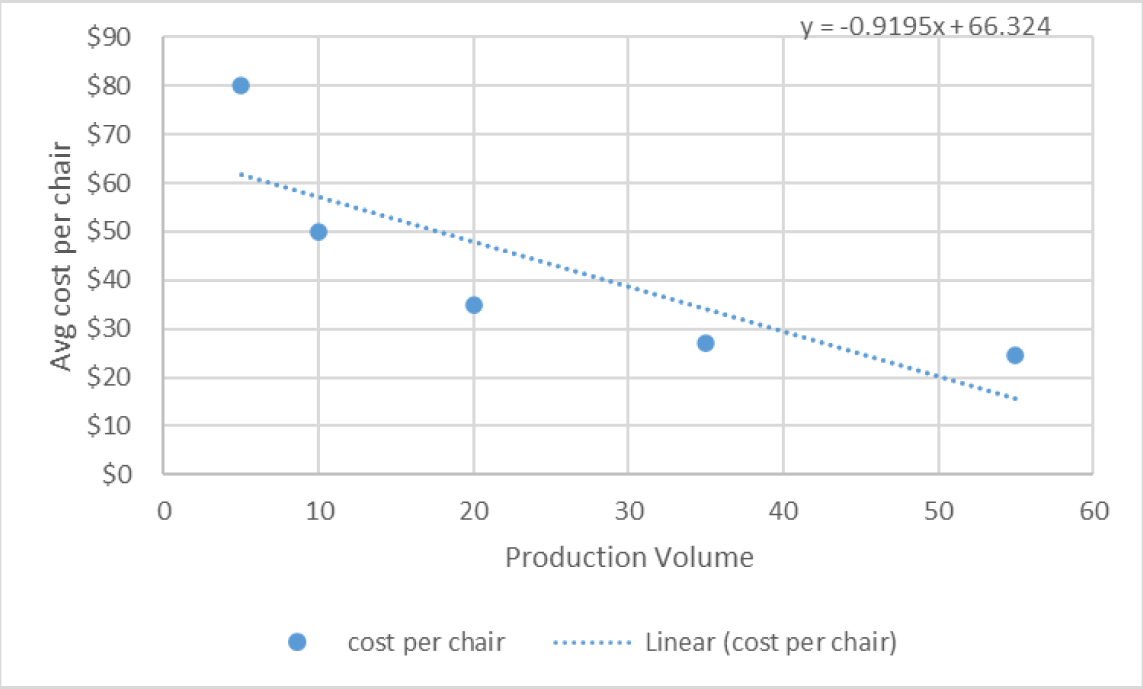
We could try models of different mathematical forms. But this straight line is the one that’s on average closest to the actual data we’re given. And from this model we can now estimate the cost for any volume.
Models for Managing computational design
For managing computational designs, we don’t have simple mathematical models derived from first principles. The manufacturing cost example above relates to simple numbers. But for computational designs, we have to model the full breadth of product-related data and processes. What might such a model be like?
Before we talk about that specifically, let’s talk about modeling another human-driven process in designing products – classification and labeling.
As a simple example, let’s consider recognizing different product categories (chairs, phones, etc.) from images. One thing we could do is get example images for each type. Then to find out if a new image is of a particular category, like chairs, we could compare it to our samples. But as humans we recognize products even with variations in angle, color, etc. Our brain does something better—that neural network models can emulate.
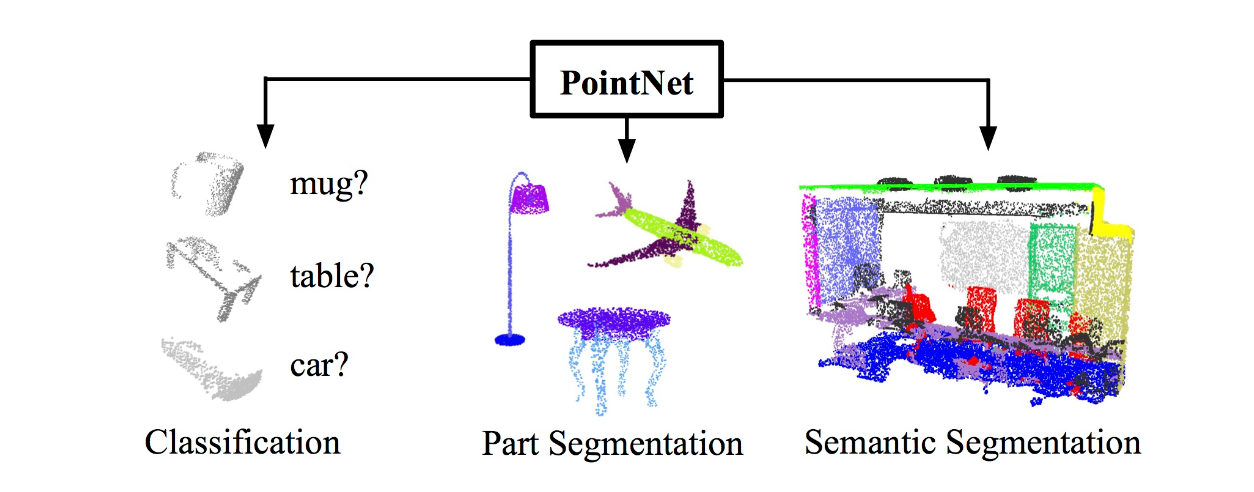
When we made a cost model from numbers, we took a value x and computed a formula. Image recognition treats pixel values as variables xi and constructs a function that—when evaluated—classifies the image. It might involve millions of operations, and is typically a neural network. We can treat it as a black box. Feed in product images as arrays of pixel values and get out a label. It doesn’t literally match samples; it recognizes products despite variations, aligning with human judgements, not just on training data but new images. This works for some human-like tasks – see the example below from Stanford’s PointNet, empirical results show neural networks can classify product images like humans, though we lack a simple theory of why.
Product design has much richer data than images. Just like image recognition, learning a model from past product data that connects all these elements, capturing stylistic and geometric similarities can support integrated decision-making. Properties like overall shape, polygon count, curvature, etc. can be encoded numerically. Models used for similar purposes or that fit a common style may cluster together. Analogous to word analogies, arithmetic on model embeddings may capture semantic relationships between models.
Such models are complex and need to overcome several challenges:
- Structured vs. Unstructured Data: CAD and ECAD models are structured data with specific formats, constraints, and relationships among components. Generative models like GPT-3 are typically designed for unstructured data.
- Dimensionality: 3D CAD models involve spatial information, which adds an extra dimension of complexity compared to 2D data like text or images.
- Complexity of CAD and ECAD Models: CAD and ECAD models are highly complex, containing intricate details, geometries, and components.
- Context and Intent Alignment: 3D models do not explicitly specify the intended context or purpose. For example, a car may be designed considering both speed and safety aspects or a building to balance energy efficiency and structural integrity.
- Design vs manufacturing feasibility: a significant challenge arises in imparting the model with an understanding of design vs manufacturing feasibility. The model may generate designs that are physically unviable or impractical for manufacturing.
The Practice and Lore of PLM Model Training
Advances in data science have brought many techniques for training models. It is part art – learned through experience more than rigid theory. To train a generative model that can potentially be used to generate 3D CAD (Computer-Aided Design) and ECAD (Electronic Computer-Aided Design) models:
- We would need a large dataset of existing CAD and ECAD models. These models should cover a wide range of designs, variations, and complexity levels.
- High-quality training data should include annotations and metadata to describe the relationships and properties of different components within the models. This data can help the model understand the structure of CAD/ECAD models.
- CAD models are often stored in proprietary formats like SolidWorks, AutoCAD, or CATIA. We might need to convert these into a common format (e.g., STEP or STL) before using them for training.
- Ensure that the training data includes a representative sample of real-world designs and variations encountered in manufacturing.
💡Guess what, PLM has got all these data. 🎉🙌
As engineering teams use CAD/ECAD tools to design products, the PLM platform captures different versions and iterations of the CAD/ECAD models. These models are stored in the PLM vaults, often using standard exchange formats like STEP or IGES to ensure compatibility across different authoring tools.
Over the lifetime of a company, the PLM system collects vast libraries of CAD/ECAD models representing real-world products designed and engineered. A single large manufacturer may have millions of models in their PLM system, capturing decades of design history across multiple product lines.
PLM platforms also typically integrate capabilities to manage classification and other metadata, revisions, dependencies, and relationships between components. This data provides critical context on how the CAD/ECAD models are structured.
With years of accumulated design data, a PLM repository contains a goldmine of training data for developing AI and machine learning models.
By leveraging CAD/ECAD models already managed in a manufacturing PLM platform, along with their metadata, we have immediate access to large volumes of high-quality, real-world training data to develop a generative model for CAD/ECAD applications. The PLM platform both solves the data collection challenge, and provides the domain structure needed to interpret the data for ML.
New Insights from Trained Models
Stanford’s PointNet is a novel deep learning architecture that can handle various 3D recognition tasks, such as part classification and segmentation, from point clouds. Point clouds are collections of points in space, and they are often used to represent 3D objects. It is a point-based network, which means that it takes as input a set of points in space, learn the spatial relationships between points, which allows it to perform tasks such as object classification and segmentation, showing strong performance on several benchmarks, achieving state-of-the-art or comparable results.
Zoo.dev Text-to-CAD is a tool that can create starter 3D CAD models from text prompts, which can be easily imported into any CAD program. Enter some geometric description and tool will create 3D models that can be rotated and exported in various formats. Note that it cannot generate complex assemblies yet, only single parts. Also, the user needs to provide precise instructions, not just object names, but it provides impressive results to accelerate the transition from design intent to CAD model creation.

Researchers from MIT, University of Washington, Harvard University, among others, in a significant collaborative effort across multiple research groups did a holistic evaluation of the potential of large language models across the entire computational design and manufacturing pipeline. The authors conclude that LLMs have the potential to revolutionize design and manufacturing by enabling faster and more efficient workflows, reducing the need for human expertise, and improving the quality of designs.
The paper provides several examples of how LLMs can assist with generating design concepts, converting text-based prompts into design specifications, and predicting the performance of a design.
One example is using LLMs to generate design variations based on a text-based prompt, such as “a chair that is comfortable and lightweight.”
We can extend this example with using LLMs to generate design concepts based on a set of constraints, such as “a bridge that can span 100 meters and withstand a certain amount of weight.”

LLMs can also be used to generate design concepts that are optimized for specific performance metrics, such as minimizing material usage or maximizing energy efficiency. Importantly, they can be optimized for multiple performance metrics simultaneously, which could be particularly useful in complex design tasks.
A few usage scenarios:
- Create 3D models from scratch: by providing the model with a description of the desired 3D model, either in natural language or in a more structured format. For example, describe the vision by saying something like, “I want a modern chair with a curved backrest, metal legs, and a leather seat.”
- Edit existing 3D models: by providing the model with a description of the desired changes, or by simply manipulating the model’s controls. For example, instruct the AI by saying, “In this car model, make the roof convertible, change the color to red, and add alloy wheels.”
- Generate 3D models from 2D drawings: or vice versa. By providing the model with a description of the desired 2D drawing, or by simply exporting the 3D model to a 2D format. For example, if you have a 2D legacy drawing and want to convert it to 3D assembly
- Iteration Support: by providing feedback on errors so the model could create multiple iterations or correct issues.
- Modularity Support: by providing instructions to the model to reuse or adapt the existing designs and solutions. For example, designing a complex piece of machinery composed of multiple parts, you can instruct the model to reuse certain components.
- Improve the efficiency and accuracy of 3D modeling and drawing workflows: In addition to these direct applications, it can also be used to improve the efficiency and accuracy of 3D modeling and drawing workflows. For example, they can be used to generate 3D models from point clouds, or to repair damaged 3D models.
Would PLM Models Work?
The capabilities of these models seem impressive – but how can they capture complex product lifecycles encompassing so many technical, commercial and operational factors? Perhaps there are undiscovered aspects unique to human cognition?
We can’t mathematically prove that PLM models would work, but as pure statistical models, the kinds of ChatGPT & Dall-E can succeed, the scale of data points from a comprehensive PLM model may imply lifecycles have a learnable structure, with an underlying simplicity and scientifically systematic than we realized.
Trained models represent knowledge, but not necessarily wisdom. I believe human expertise would remain vital for guiding model usage and interpreting results. We must validate the output from these tools and examine them skeptically, as models have limitations despite good performance on their core tasks. Still, combining learned models with human judgment promises to accelerate knowledge discovery – a virtuous cycle of data, models and insights powering continuous improvement.
So as both a science and an art, when practitioners combine model architectures, data and algorithms to create PLM models with the complexities of integrated product lifecycles may open opening exciting opportunities to improve product development.